QuickStart Tutorial¶
This is a quickstart tutorial to run the OpusDistillery pipeline from scratch on your local machine for learning purposes. In this example, we will use OPUS-MT models for sequence-level distillation from a multilingual teacher into a multilingual student.
Pipeline Overview¶
Below is an overview of the pipeline steps:
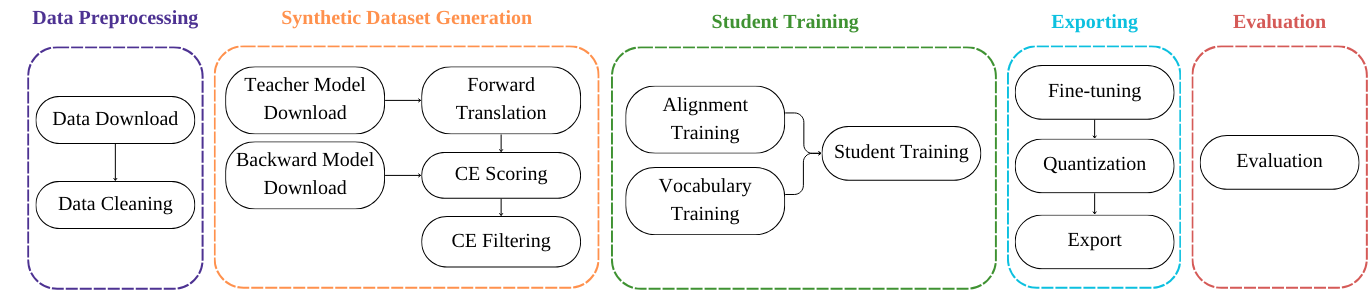
The pipeline consists of five main steps:
Data Preprocessing: Downloads data from publicly available repositories and handles basic data cleaning.
Synthetic Dataset Generation: Downloads the relevant teacher and backward models, forward translates all source sentences with our teacher model(s) into the target languages, computes cross-entropy scores with a backward model, and then filters the synthetic dataset.
Student Training: Trains a small transformer model on the filtered synthetic dataset with guided alignment.
Exporting: Creates the final student. It includes a fine-tuning step, a quantization step and, finally, the export step which saves the model so it is ready for deployment.
Evaluation: Evaluates the trained model.
For a more detailed description of the pipeline, refer to the Pipeline Steps section.
Pipeline Setup¶
In this tutorial, we will be running the pipeline locally.
Clone the repository:
git clone https://github.com/Helsinki-NLP/OpusDistillery.git
Install Mamba, a fast Conda package manager:
make conda
Install Snakemake:
make snakemake
Update the git submodules:
make git-modules
Edit the local profile in profiles/local/config.yaml and specify the data directory path as the root value in the config section. This folder will store all pipeline outputs:
root=/home/degibert/Documents/0_Work/OpusDistillery/data
Ensure everything is installed properly:
source ../mambaforge/etc/profile.d/conda.sh ; conda activate ; conda activate snakemake
pip install -r requirements.txt
make dry-run CONFIG="configs/config.quickstart.yml" PROFILE="local"
Experiment Setup¶
Let’s define a simple configuration file in YAML format. We will use configs/config.quickstart.yml.
We define the directory structure (
data-dir/test/fiu-eng) and specify the language pairs of the student model we want to distill:
experiment:
dirname: test
name: fiu-eng
langpairs:
- et-en
- fi-en
- hu-en
We define the OPUS-MT models that we want to use for forward translation and for backward scoring:
#URL to the OPUS-MT model to use as the teacher
opusmt-teacher: "https://object.pouta.csc.fi/Tatoeba-MT-models/fiu-eng/opus4m-2020-08-12.zip"
#URL to the OPUS-MT model to use as the backward model
opusmt-backward: "https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.zip"
Since the backward model is multilingual on the target side, so we need to specify it:
one2many-backward: True
Define the metric to select the best model:
best-model: perplexity
Define the maximum number of lines for splitting files during forward translation:
split-length: 1000
Running the pipeline¶
To run the pipeline, execute:
make run CONFIG="configs/config.quickstart.yml" PROFILE="local"
You can also create a directed acyclic graph (DAG) to represent the steps the pipeline will take:
make dag CONFIG="configs/config.quickstart.yml" PROFILE="local"
This will generate the file DAG.pdf in the root directory, showing the steps for this specific run.
By default, all Snakemake rules are executed. To run the pipeline up to a specific rule, use:
make run CONFIG="configs/config.quickstart.yml" PROFILE="local" TARGET="/home/degibert/Documents/0_Work/OpusDistillery/data/data/test/fiu-eng/original/et-en/devset.source.gz"