Fine-tuning a model in the OPUS-CAT Trados plugin
Fine-tuning is a method of adapting an MT model to a given domain or style. Fine-tuning requires a collection of bilingual sentences (with same source and target languages as the model to be fine-tuned), which represent the domain or style that the MT model should adapt to. For instance, a model can be adapted for medical translation by fine-tuning it with bilingual medical texts. Fine-tuning may take several hours, but it can improve MT quality significantly.
OPUS-CAT MT models can be fine-tuned by using a custom batch task contained in the OPUS-CAT Trados plugin. (Models can also be fine-tuned directly in the OPUS-CAT MT Engine, but the Trados plugin fine-tuning allows for more targeted selection of fine-tuning sentences).
The name of the fine-tuning custom batch is OPUS-CAT Finetune. When this task is performed for a translation project, it extracts relevant sentence pairs from the project files and file translation memories to use as fine-tuning material. Then the task sends the fine-tuning material to the OPUS-CAT MT Engine, which performs the fine-tuning. Because the actual fine-tuning work happens in the OPUS-CAT MT Engine, Trados can be used normally during the duration of the fine-tuning. The progress of the fine-tuning can be monitored in the OPUS-CAT MT Engine.
OPUS-CAT Finetune task extracts sentence pairs for fine-tuning from two different sources:
- Existing translations present in the translation project
- File-based translation memories included in the project
The existing translations are the primary source, since they are directly relevant to the translation project. The new translations must remain consistent with these existing translations, so they are especially valuable for fine-tuning MT models. Many translation projects contain so many existing translations that they can be used alone as fine-tuning material.
If the project does not contain enough existing translations, sentence pairs can also be extracted from the translation memories, starting with full and fuzzy matches for the source sentences in the project. Fine-tuning requires a minimum of 500 sentence pairs (although results will probably not be good with such a low amount).
The maximum amount of fine-tuning sentence pairs is 50,000 in the Trados plugin (larger fine-tuning sets can be used when fine-tuning directly in the OPUS-CAT MT Engine. This restriction is in place as the fine-tuning batch task is intended to be used for extracting fine-tuning material that is directly relevant to the current translation job, which generally means an amount of sentence pairs in the tens of thousands at most.
When the fine-tuning is complete, the fine-tuned model can be used in the Trados plugin by selecting the tag of the fine-tuned model in the settings of the OPUS-CAT translation provider.
Accessing the OPUS-CAT Finetune batch task
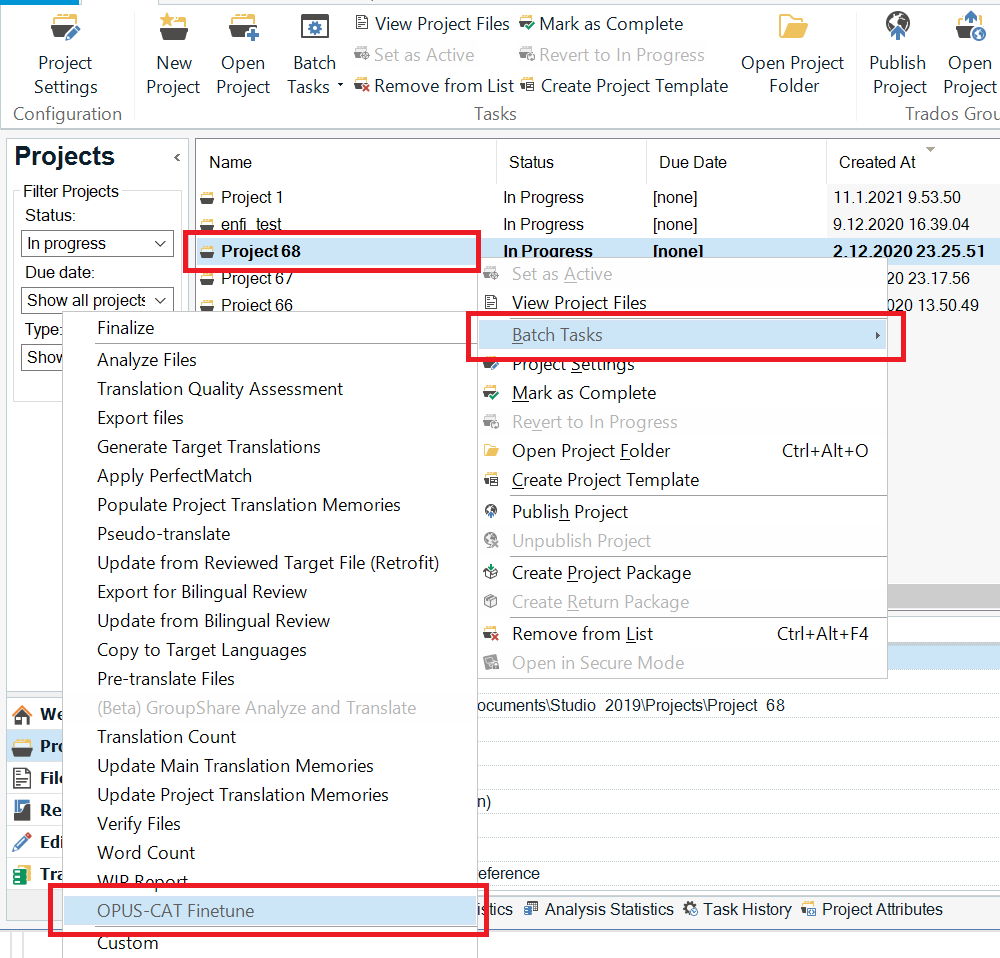
The OPUS-CAT Finetune batch task can be accessed in Trados Studio by right-clicking a project in the Projects view of Trados Studio and selecting Batch tasks and OPUS-CAT Finetune:
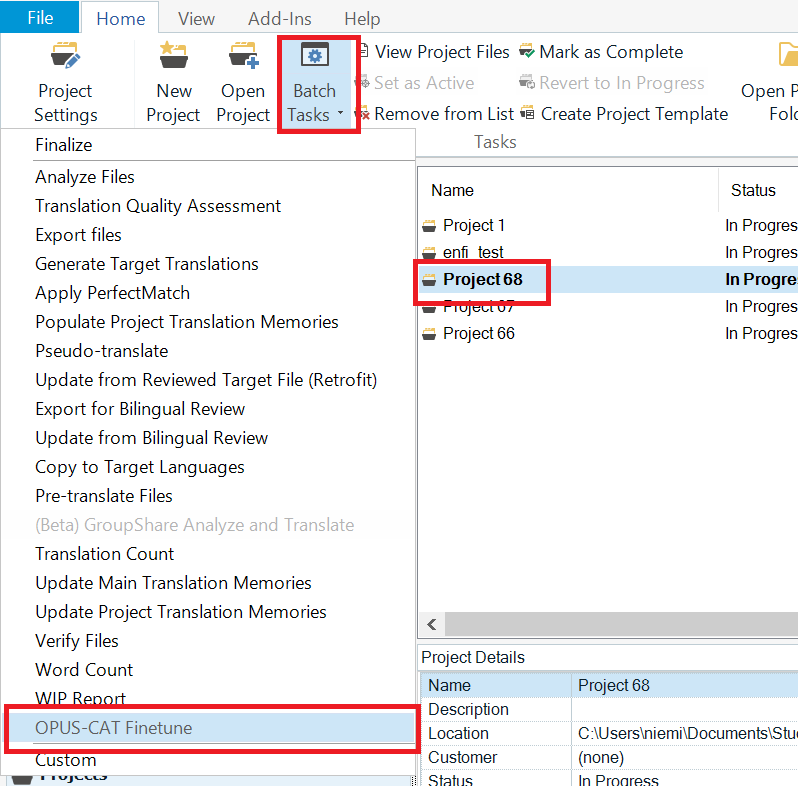
An alternative way is to select a project in the Projects view, click the Batch Tasks icon on the Home ribbon, and then select OPUS-CAT Finetune:
Selecting files for the OPUS-CAT Finetune batch task
After you select OPUS-CAT Finetune, the Batch Processing window opens:
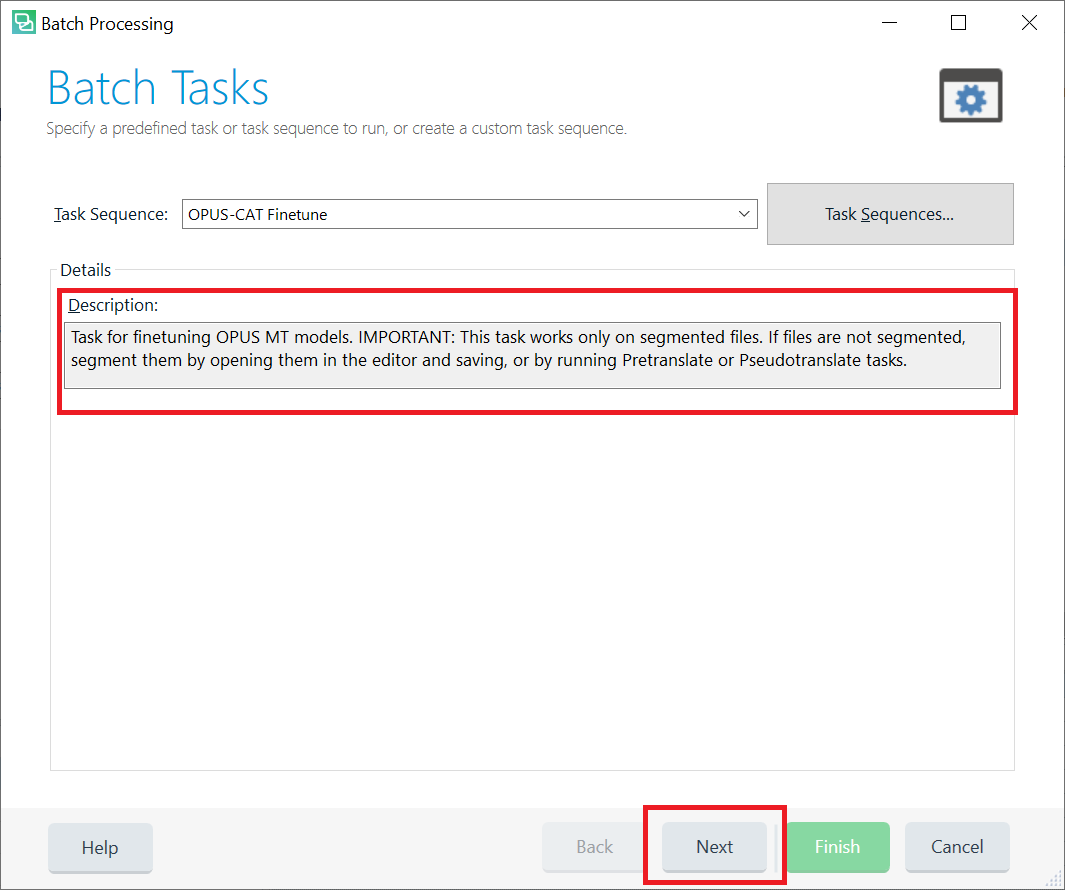
In the Description field there is a note about making sure that the target files are segmented before running the task. If you are not sure whether the files are segmented, running the Pre-Translate Files batch task will segment them. If you have created the project with one of the Prepare task sequences (the default task sequence), Pre-Translate Files has already been performed, and the files are segmented. If you are sure the files are segmented, Click Next
On the Files page of Batch Processing window, you can select the files which will be used in the fine-tuning process. All files are selected by default, and this is usually the best option, but you can exclude some files by clearing their checkboxes:
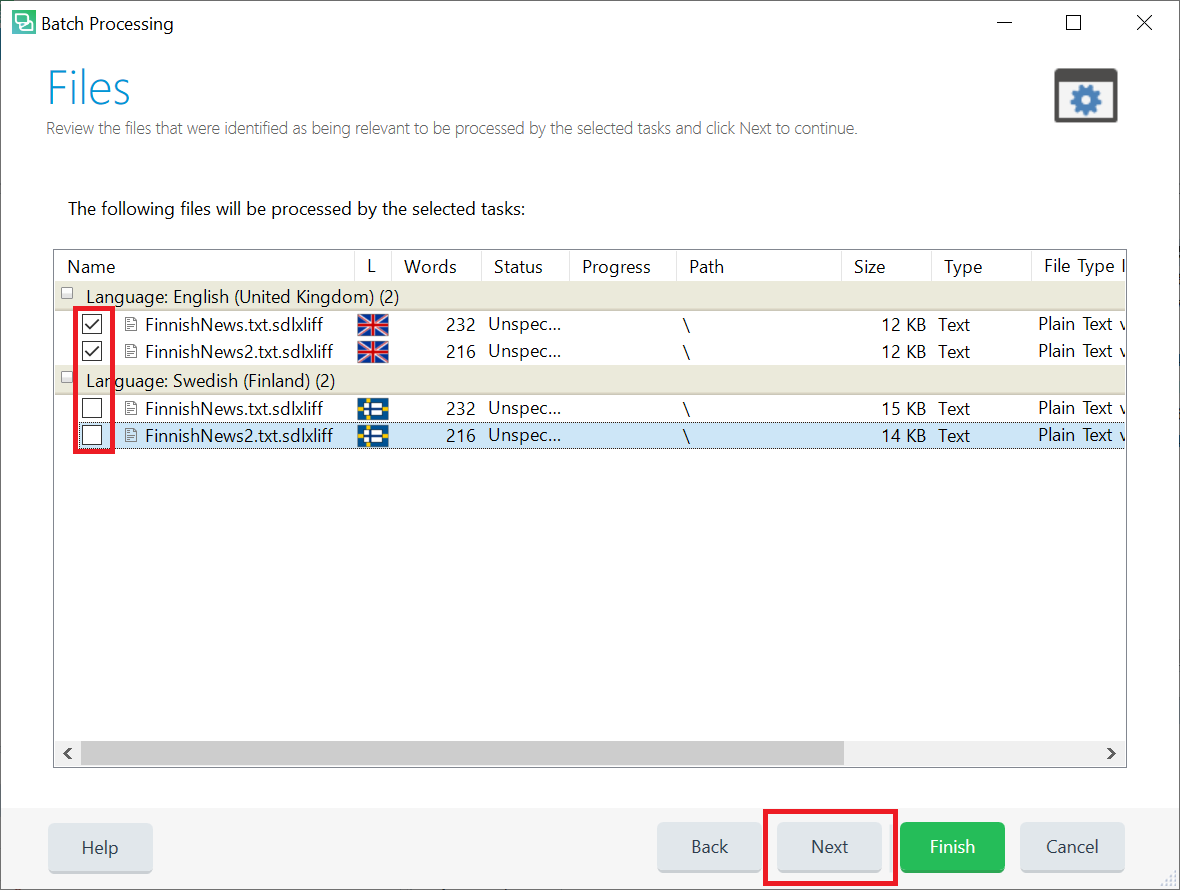
NOTE: OPUS-CAT Finetune batch task can be performed for only one target language at a time. If the project contains multiple target languages, refer to Projects with multiple target languages.
The settings of the OPUS-CAT Finetune batch task
When you click Next on the Files page of Batch Processing window, the Settings page opens and OPUS-CAT Finetune settings are displayed.
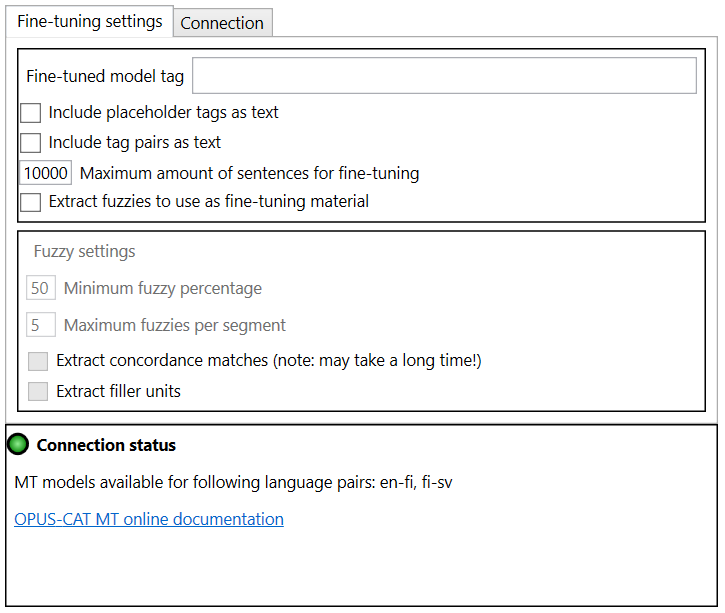
The main settings are located at the top of the window:

- Fine-tuned model tag: The text entered in this field will be used as the initial tag of the fine-tuned model. Tags can be used to specify that a certain model should be used for producing translations. The name of the fine-tuned model is formed by adding the text entered here as a suffix to the name of the base model. For example, if the name of the original model is opus-2021-02-04 and the finetuned is entered here, the name of the fine-tuned model will be opus-2021-02-04_finetuned.
- Include placeholder tags as texts and Include tag pairs as texts: Bilingual files may contain tags. The base OPUS models that OPUS-CAT uses do not support translation of tagged text, instead the tags are stripped away before the text is translated, and the resulting machine translation contains no tags. However, when fine-tuning a model, it is possible to specify that tags are to be included in the fine-tuning material as text markers. This allows the fine-tuned model to learn how to place the text markers in the translation. If a model has been fine-tuned with these options, the Trados plugin will attempt to place tags to the translation based on these text markers. This is an experimental feature, so it is disabled by default.
- Maximum amount of sentences for fine-tuning: The maximum amount of sentence pairs to be extracted from the project files can be specified here. This option can be used to limit the duration of fine-tuning (the more sentences pairs there are, the longer the fine-tuning will take).
- Extract fuzzies to use as fine-tuning material: If this option is selected, matches from the translation memories added to the project will also be extracted as fine-tuning material (up to the specified maximum amount of sentence pairs). When this option is enabled, the Fuzzy settings pane will be enabled, and fuzzy match extraction settings can be set.
Fuzzy settings
The options in the Fuzzy settings pane specify how sentence pairs are extracted from the file translation memories that have been added to the project. Translation memory matches are extracted for each new segment in the translation project.

The following settings are available:
-
Minimum fuzzy percentage: Only translation memory matches with a match percentage equal to or higher than the value of this setting will be extracted as fine-tuning material. Matches with high percentages are generally more relevant to the translation job at hand. If you set this value very low (less than 50), some of the matches may be completely irrelevant to the current job (for instance, the source segment of the match might only share a single common word such as “this” with the new segment). This is why it is recommended to use a value higher than 50 for this setting.
-
Maximum fuzzies per segment: This setting determines the maximum amount of translation memory matches extracted per each segment. This value should be kept reasonably low (5-10), since setting it too high may make the fine-tuning material too homogeneous (for instance with translation memories where there are many similar matches).
-
Extract concordance matches: This option can be used to extract concordance matches, which are sentence pairs where the source segment contains one of the words from the new segments in the project. For the most common source languages, the most frequently used words are filtered out before extracting concordance matches by using a list of stop words (https://github.com/stopwords-iso). For instance, for the English sentence “the cat sat on the mat” concordance matches would only be extracted for the words “cat” and “mat”, as the other words are very common and therefore included in the stop word list. Extracting concordance matches is more time-consuming than other methods of extracting fine-tuning material from translation memories. Concordance matches are not as relevant to the current job as normal translation memory matches, but they are more relevant than randomly extracted sentence pairs.
-
Extract filler units: If this option is checked, sentence pairs are extracted from the translation memory until the amount of sentence pairs specified in Maximum amount of sentences for fine-tuning is reached. The sentence pairs are extracted based on their creation date and time, and newest sentence pairs are extracted first. This option is useful if a sufficient amount of fine-tuning material cannot be extracted with the other extraction methods.
Initiating fine-tuning
When the options have been set, fine-tuning can be initiated by clicking Finish in the bottom of the Batch Processing window:
When you click Finish the batch task will start processing the files in the project one by one. A progress bar indicates the percentage of source segments processed so far:
Once all the source segments in the project files have been processed, the progress bar will disappear, but the batch task will still perform some processing on the extracted source segments. The green Close button in the bottom of the window will remain greyed out until this processing has been finished.
NOTE: The extraction of sentence pairs from translation memories takes place during this period between the disappearance of the progress bar and the activation of the Close button. Depending on the extraction settings (and especially on whether the Extract concordance matches option has been enabled), the extraction may take a considerable time, during which no indication of progress is shown. If the batch task is taking too long, it can be canceled by clicking Cancel. If Extract concordance matches is not enabled, the batch task should finish reasonably quickly.
Once the processing is complete, the Close button is enabled and you can close the Batch Processing window by clicking it. The batch task has sent the extracted sentence pairs to OPUS-CAT MT Engine, which will have started the fine-tuning process. You can check that this has taken place by navigating to the OPUS-CAT MT Engine:
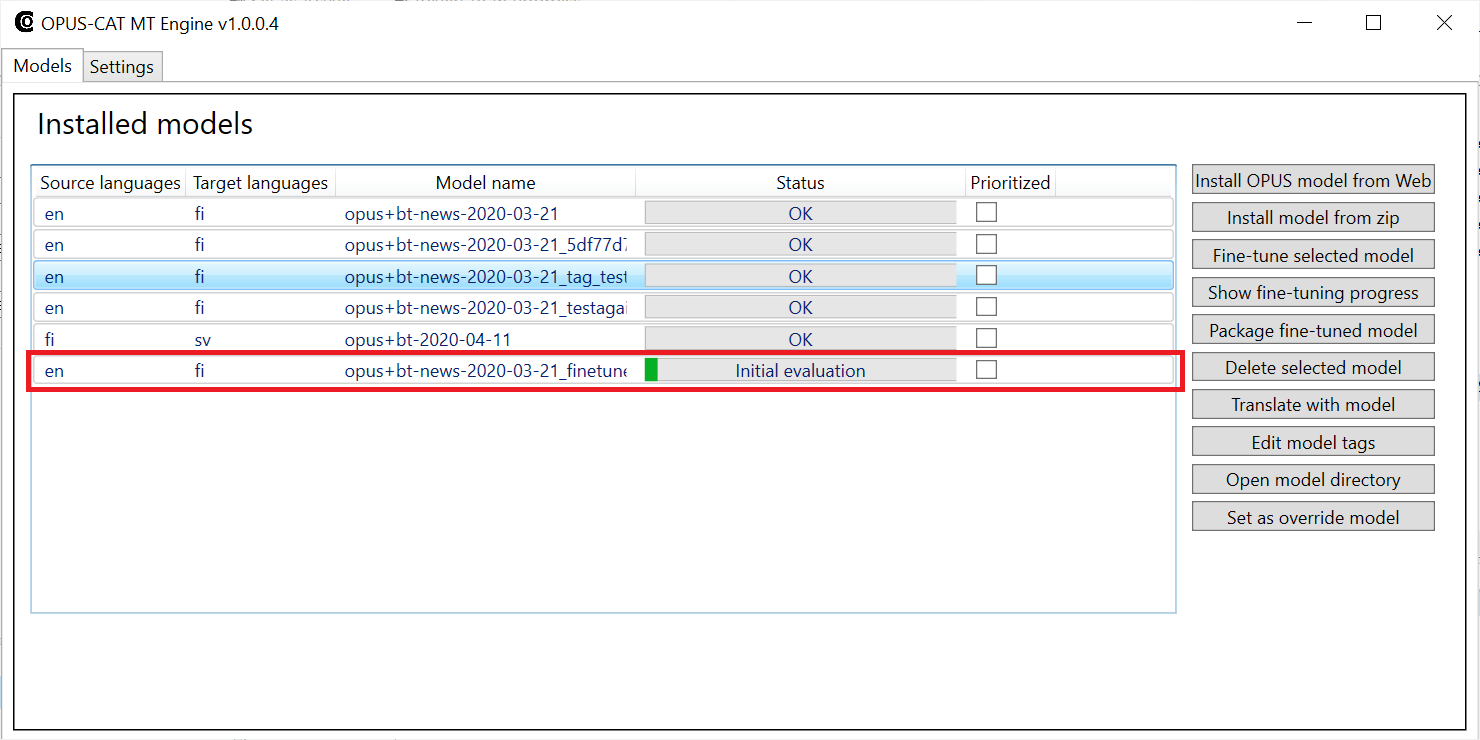
More information about monitoring the progress of fine-tuning can be found here.
Projects with multiple target languages
OPUS-CAT Finetune batch task can be performed for only one target language at a time. If you have multiple target languages, deselect the files for all but one of the target languages before proceeding. If there are too many files to deselect, open the Files view of Trados Studio:
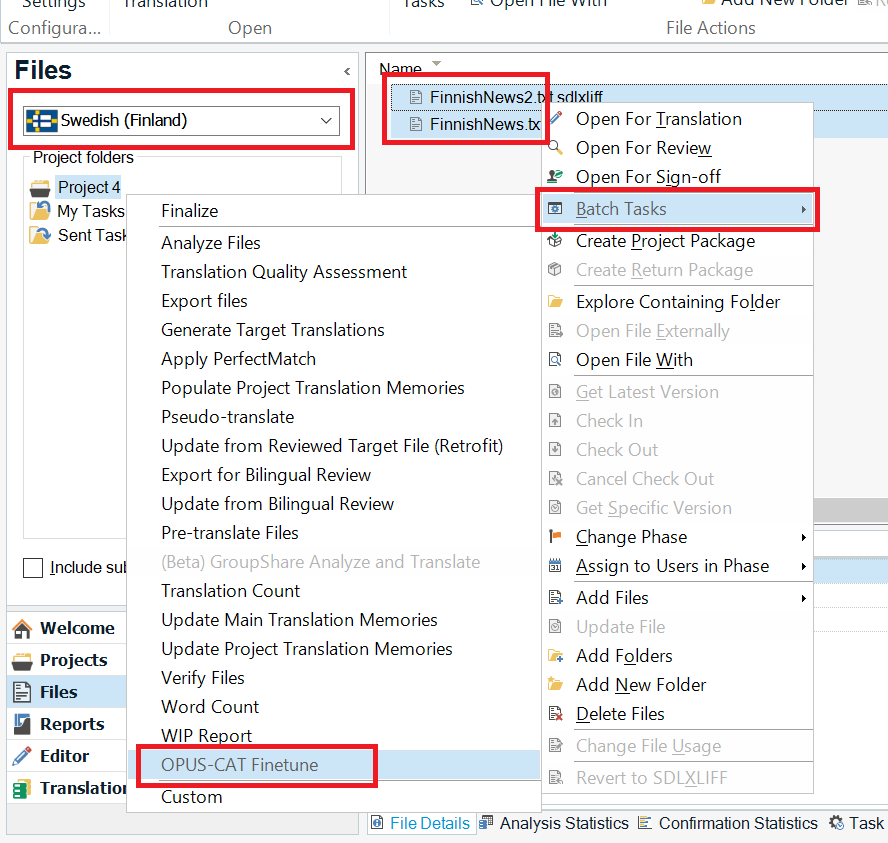
In the Files view only files of single target language are shown at a time (you can change the target language on the left). Select all files for the target language, then right-click one of the selected files, select Batch tasks and then select OPUS-CAT Finetune. When a batch is initiated in this way, the Files page of the Batch Processing window will be skipped and the batch task is performed only for the files selected in the Files view.